

In 1962, JFK challenged Americans to send a man to the moon by the end of the decade, inspiring a heroic engineering effort that culminated in Neil Armstrong’s first steps on the lunar surface. Many of the fruits of this engineering effort were highly visible and sexy—there were new spacecraft, new spacesuits, and moon buggies. But the Apollo Program was so staggeringly complex that new technologies had to be invented even to do the mundane things. One of these technologies was IBM’s Information Management System (IMS).
IMS is a database management system. NASA needed one in order to keep track of all the parts that went into building a Saturn V rocket, which—because there were two million of them—was expected to be a challenge. Databases were a new idea in the 1960s and there weren’t any already available for NASA to use, so, in 1965, NASA asked IBM to work with North American Aviation and Caterpillar Tractor to create one. By 1968, IBM had installed a working version of IMS at NASA, though at the time it was called ICS/DL/I for “Informational Control System and Data Language/Interface.” (IBM seems to have gone through a brief, unfortunate infatuation with the slash; see PL/I.) Two years later, IBM rebranded ICS/DL/I as “IMS” and began selling it to other customers. It was one of the first commercially available database management systems.
The incredible thing about IMS is that it is still in use today. And not just on a small scale: Banks, insurance companies, hospitals, and government agencies still use IMS for all sorts of critical tasks. Over 95% of Fortune 1000 companies use IMS in some capacity, as do all of the top five US banks.1 Whenever you withdraw cash from an ATM, the odds are exceedingly good that you are interacting with IMS at some point in the course of your transaction. In a world where the relational database is an old workhorse increasingly in competition with trendy new NoSQL databases, IMS is a freaking dinosaur. It is a relic from an era before the relational database was even invented, which didn’t happen until 1970. And yet it seems to be the database system in charge of all the important stuff.
I think this makes IMS pretty interesting. Depending on how you feel about relational databases, it either offers insight into how the relational model improved on its predecessors or else exemplifies an alternative model better suited to certain problems.
IMS works according to a hierarchical model, meaning that, instead of thinking about data as tables that can be brought together using JOIN operations, IMS thinks about data as trees. Each kind of record you store can have other kinds of records as children; these child record types represent additional information that you might be interested in given a record of the parent type.
To take an example, say that you want to store information about bank customers. You might have one type of record to represent customers and another type of record to represent accounts. Like in a relational database, where each table has columns, these records will have different fields; we might want to have a first name field, a last name field, and a city field for each customer. We must then decide whether we are likely to first lookup a customer and then information about that customer’s account, or whether we are likely to first lookup an account and then information about that account’s owner. Assuming we decide that we will access customers first, then we will make our account record type a child of our customer record type. Diagrammed, our database model would look something like this:2
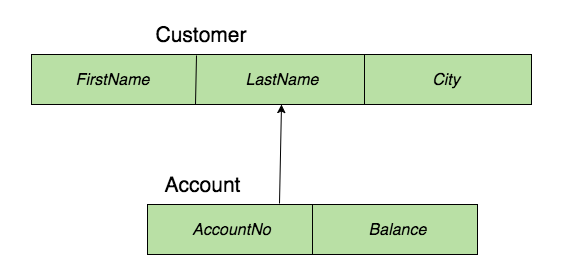
And an actual database might look like:
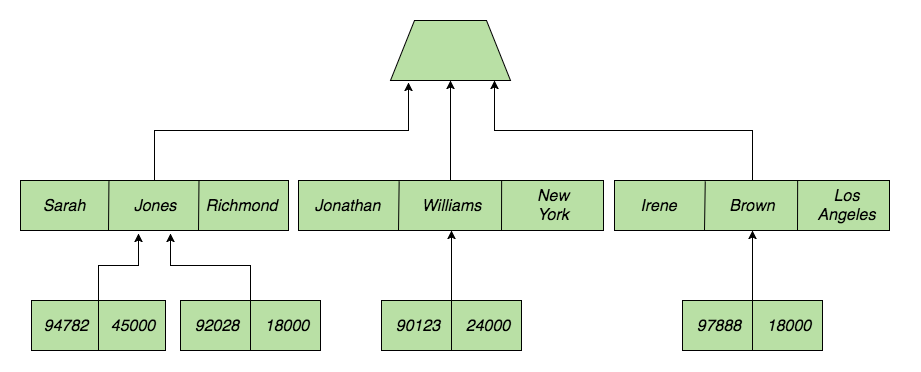
By modeling our data this way, we are hewing close to the reality of how our data is stored. Each parent record includes pointers to its children, meaning that moving down our tree from the root node is efficient. (Actually, each parent basically stores just one pointer to the first of its children. The children in turn contain pointers to their siblings. This ensures that the size of a record does not vary with the number of children it has.) This efficiency can make data accesses very fast, provided that we are accessing our data in ways that we anticipated when we first structured our database. According to IBM, an IMS instance can process over 100,000 transactions a second, which is probably a large part of why IMS is still used, particularly at banks.3 But the downside is that we have lost a lot of flexibility. If we want to access our data in ways we did not anticipate, we will have a hard time.
To illustrate this, consider what might happen if we decide that we would like to access accounts before customers. Perhaps customers are calling in to update their addresses, and we would like them to uniquely identify themselves using their account numbers. So we want to use an account number to find an account, and then from there find the account’s owner. But since all accesses start at the root of our tree, there’s no way for us to get to an account efficiently without first deciding on a customer. To fix this problem, we could introduce a second tree or hierarchy starting with account records; these account records would then have customer records as children. This would let us access accounts and then customers efficiently. But it would involve duplicating information that we already have stored in our database—we would have two trees storing the same information in different orders. Another option would be to establish an index of accounts that could point us to the right account record given an account number. That would work too, but it would entail extra work during insert and update operations in the future.
It was precisely this inflexibility and the problem of duplicated information that pushed E. F. Codd to propose the relational model. In his 1970 paper, A Relational Model of Data for Large Shared Data Banks, he states at the outset that he intends to present a model for data storage that can protect users from having to know anything about how their data is stored. Looked at one way, the hierarchical model is entirely an artifact of how the designers of IMS chose to store data. It is a bottom-up model, the implication of a physical reality. The relational model, on the other hand, is an abstract model based on relational algebra, and is top-down in that the data storage scheme can be anything provided it accommodates the model. The relational model’s great advantage is that, just because you’ve made decisions that have caused the database to store your data in a particular way, you won’t find yourself effectively unable to make certain queries.
All that said, the relational model is an abstraction, and we all know abstractions aren’t free. Banks and large institutions have stuck with IMS partly because of the performance benefits, though it’s hard to say if those benefits would be enough to keep them from switching to a modern database if they weren’t also trying to avoid rewriting mission-critical legacy code. However, today’s popular NoSQL databases demonstrate that there are people willing to drop the conveniences of the relational model in return for better performance. Something like MongoDB, which encourages its users to store data in a denormalized form, isn’t all that different from IMS. If you choose to store some entity inside of another JSON record, then in effect you have created something like the IMS hierarchy, and you have constrained your ability to query for that data in the future. But perhaps that’s a tradeoff you’re willing to make. So, even if IMS hadn’t predated E. F. Codd’s relational model by several years, there are still reasons why IMS’ creators might not have adopted the relational model wholesale.
Unfortunately, IMS isn’t something that you can download and take for a spin on your own computer. First of all, IMS is not free, so you would have to buy it from IBM. But the bigger problem is that IMS only runs on IBM mainframes like the IBM z13. That’s a shame, because it would be a joy to play around with IMS and get a sense for exactly how it differs from something like MySQL. But even without that opportunity, it’s interesting to think about software systems that work in ways we don’t expect or aren’t used to. And it’s especially interesting when those systems, alien as they are, turn out to undergird your local hospital, the entire financial sector, and even the federal government.
If you enjoyed this post, more like it come out every four weeks! Follow @TwoBitHistory on Twitter or subscribe to the RSS feed to make sure you know when a new post is out.
-
Klein, Barbara. An Introduction to IMS: Your Complete Guide to IBM Information Management System. IBM Press, 2012. ↩
-
https://www.slideshare.net/roberthain/ims05-ims-100-k-benchmark ↩