

In 2001, Tim Berners-Lee, inventor of the World Wide Web, published an article in Scientific American. Berners-Lee, along with two other researchers, Ora Lassila and James Hendler, wanted to give the world a preview of the revolutionary new changes they saw coming to the web. Since its introduction only a decade before, the web had fast become the world’s best means for sharing documents with other people. Now, the authors promised, the web would evolve to encompass not just documents but every kind of data one could imagine.
They called this new web the Semantic Web. The great promise of the Semantic Web was that it would be readable not just by humans but also by machines. Pages on the web would be meaningful to software programs—they would have semantics—allowing programs to interact with the web the same way that people do. Programs could exchange data across the Semantic Web without having to be explicitly engineered to talk to each other. According to Berners-Lee, Lassila, and Hendler, a typical day living with the myriad conveniences of the Semantic Web might look something like this:
The entertainment system was belting out the Beatles’ “We Can Work It Out” when the phone rang. When Pete answered, his phone turned the sound down by sending a message to all the other local devices that had a volume control. His sister, Lucy, was on the line from the doctor’s office: “Mom needs to see a specialist and then has to have a series of physical therapy sessions. Biweekly or something. I’m going to have my agent set up the appointments.” Pete immediately agreed to share the chauffeuring. At the doctor’s office, Lucy instructed her Semantic Web agent through her handheld Web browser. The agent promptly retrieved the information about Mom’s prescribed treatment within a 20-mile radius of her home and with a rating of excellent or very good on trusted rating services. It then began trying to find a match between available appointment times (supplied by the agents of individual providers through their Web sites) and Pete’s and Lucy’s busy schedules.1
The vision was that the Semantic Web would become a playground for intelligent “agents.” These agents would automate much of the work that the world had only just learned to do on the web.

For a while, this vision enticed a lot of people. After new technologies such as AJAX led to the rise of what Silicon Valley called Web 2.0, Berners-Lee began referring to the Semantic Web as Web 3.0. Many thought that the Semantic Web was indeed the inevitable next step. A New York Times article published in 2006 quotes a speech Berners-Lee gave at a conference in which he said that the extant web would, twenty years in the future, be seen as only the “embryonic” form of something far greater.2 A venture capitalist, also quoted in the article, claimed that the Semantic Web would be “profound,” and ultimately “as obvious as the web seems obvious to us today.”
Of course, the Semantic Web we were promised has yet to be delivered. In 2018, we have “agents” like Siri that can do certain tasks for us. But Siri can only do what it can because engineers at Apple have manually hooked it up to a medley of web services each capable of answering only a narrow category of questions. An important consequence is that, without being large and important enough for Apple to care, you cannot advertise your services directly to Siri from your own website. Unlike the physical therapists that Berners-Lee and his co-authors imagined would be able to hang out their shingles on the web, today we are stuck with giant, centralized repositories of information. Today’s physical therapists must enter information about their practice into Google or Yelp, because those are the only services that the smartphone agents know how to use and the only ones human beings will bother to check. The key difference between our current reality and the promised Semantic future is best captured by this throwaway aside in the excerpt above: “…appointment times (supplied by the agents of individual providers through their Web sites)…”
In fact, over the last decade, the web has not only failed to become the Semantic Web but also threatened to recede as an idea altogether. We now hardly ever talk about “the web” and instead talk about “the internet,” which as of 2016 has become such a common term that newspapers no longer capitalize it. (To be fair, they stopped capitalizing “web” too.) Some might still protest that the web and the internet are two different things, but the distinction gets less clear all the time. The web we have today is slowly becoming a glorified app store, just the easiest way among many to download software that communicates with distant servers using closed protocols and schemas, making it functionally identical to the software ecosystem that existed before the web. How did we get here? If the effort to build a Semantic Web had succeeded, would the web have looked different today? Or have there been so many forces working against a decentralized web for so long that the Semantic Web was always going to be stillborn?
Semweb Hucksters and Their Metacrap
To some more practically minded engineers, the Semantic Web was, from the outset, a utopian dream.
The basic idea behind the Semantic Web was that everyone would use a new set of standards to annotate their webpages with little bits of XML. These little bits of XML would have no effect on the presentation of the webpage, but they could be read by software programs to divine meaning that otherwise would only be available to humans.
The bits of XML were a way of expressing metadata about the webpage. We are all familiar with metadata in the context of a file system: When we look at a file on our computers, we can see when it was created, when it was last updated, and whom it was originally created by. Likewise, webpages on the Semantic Web would be able to tell your browser who authored the page and perhaps even where that person went to school, or where that person is currently employed. In theory, this information would allow Semantic Web browsers to answer queries across a large collection of webpages. In their article for Scientific American, Berners-Lee and his co-authors explain that you could, for example, use the Semantic Web to look up a person you met at a conference whose name you only partially remember.
Cory Doctorow, a blogger and digital rights activist, published an influential essay in 2001 that pointed out the many problems with depending on voluntarily supplied metadata. A world of “exhaustive, reliable” metadata would be wonderful, he argued, but such a world was “a pipe-dream, founded on self-delusion, nerd hubris, and hysterically inflated market opportunities.”3 Doctorow had found himself in a series of debates over the Semantic Web at tech conferences and wanted to catalog the serious issues that the Semantic Web enthusiasts (Doctorow calls them “semweb hucksters”) were overlooking.4 The essay, titled “Metacrap,” identifies seven problems, among them the obvious fact that most web users were likely to provide either no metadata at all or else lots of misleading metadata meant to draw clicks. Even if users were universally diligent and well-intentioned, in order for the metadata to be robust and reliable, users would all have to agree on a single representation for each important concept. Doctorow argued that in some cases a single representation might not be appropriate, desirable, or fair to all users.
Indeed, the web had already seen people abusing the HTML <meta> tag
(introduced at least as early as HTML 4) in an attempt to improve the
visibility of their webpages in search results. In a 2004 paper, Ben Munat,
then an academic at Evergreen State College, explains how search engines once
experimented with using keywords supplied via the <meta> tag to index
results, but soon discovered that unscrupulous webpage authors were including
tags unrelated to the actual content of their webpage.5 As a result, search
engines came to ignore the <meta> tag in favor of using complex algorithms to
analyze the actual content of a webpage. Munat concludes that a
general-purpose Semantic Web is unworkable, and that the focus should be on
specific domains within medicine and science.
Others have also seen the Semantic Web project as tragically flawed, though they have located the flaw elsewhere. Aaron Swartz, the famous programmer and another digital rights activist, wrote in an unfinished book about the Semantic Web published after his death that Doctorow was “attacking a strawman.”6 Nobody expected that metadata on the web would be thoroughly accurate and reliable, but the Semantic Web, or at least a more realistically scoped version of it, remained possible. The problem, in Swartz’ view, was the “formalizing mindset of mathematics and the institutional structure of academics” that the “semantic Webheads” brought to bear on the challenge. In forums like the World Wide Web Consortium (W3C), a huge amount of effort and discussion went into creating standards before there were any applications out there to standardize. And the standards that emerged from these “Talmudic debates” were so abstract that few of them ever saw widespread adoption. The few that did, like XML, were “uniformly scourges on the planet, offenses against hardworking programmers that have pushed out sensible formats (like JSON) in favor of overly-complicated hairballs with no basis in reality.” The Semantic Web might have thrived if, like the original web, its standards were eagerly adopted by everyone. But that never happened because—as has been discussed on this blog before—the putative benefits of something like XML are not easy to sell to a programmer when the alternatives are both entirely sufficient and much easier to understand.
Building the Semantic Web
If the Semantic Web was not an outright impossibility, it was always going to require the contributions of lots of clever people working in concert.
The long effort to build the Semantic Web has been said to consist of four phases.7 The first phase, which lasted from 2001 to 2005, was the golden age of Semantic Web activity. Between 2001 and 2005, the W3C issued a slew of new standards laying out the foundational technologies of the Semantic future.
The most important of these was the Resource Description Framework (RDF). The W3C issued the first version of the RDF standard in 2004, but RDF had been floating around since 1997, when a W3C working group introduced it in a draft specification. RDF was originally conceived of as a tool for modeling metadata and was partly based on earlier attempts by Ramanathan Guha, an Apple engineer, to develop a metadata system for files stored on Apple computers.8 The Semantic Web working groups at W3C repurposed RDF to represent arbitrary kinds of general knowledge.
RDF would be the grammar in which Semantic webpages expressed information. The grammar is a simple one: Facts about the world are expressed in RDF as triplets of subject, predicate, and object. Tim Bray, who worked with Ramanathan Guha on an early version of RDF, gives the following example, describing TV shows and movies: 9
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix ex: <http://www.example.org/> .
ex:vincent_donofrio ex:starred_in ex:law_and_order_ci .
ex:law_and_order_ci rdf:type ex:tv_show .
ex:the_thirteenth_floor ex:similar_plot_as ex:the_matrix .
The syntax is not important, especially since RDF can be represented in a
number of formats, including XML and JSON. This example is in a format called
Turtle, which expresses RDF triplets as straightforward sentences terminated by
periods. The three essential sentences, which appear above after the @prefix
preamble, state three facts: Vincent Donofrio starred in Law and Order, Law
and Order is a type of TV Show, and the movie The Thirteenth Floor has a
similar plot as The Matrix. (If you don’t know who Vincent Donofrio is and
have never seen The Thirteenth Floor, I, too, was watching Nickelodeon and
sipping Capri Suns in 1999.)
Other specifications finalized and drafted during this first era of Semantic Web development describe all the ways in which RDF can be used. RDF in Attributes (RDFa) defines how RDF can be embedded in HTML so that browsers, search engines, and other programs can glean meaning from a webpage. RDF Schema and another standard called OWL allows RDF authors to demarcate the boundary between valid and invalid RDF statements in their RDF documents. RDF Schema and OWL, in other words, are tools for creating what are known as ontologies, explicit specifications of what can and cannot be said within a specific domain. An ontology might include a rule, for example, expressing that no person can be the mother of another person without also being a parent of that person. The hope was that these ontologies would be widely used not only to check the accuracy of RDF found in the wild but also to make inferences about omitted information.
In 2006, Tim Berners-Lee posted a short article in which he argued that the existing work on Semantic Web standards needed to be supplemented by a concerted effort to make semantic data available on the web.10 Furthermore, once on the web, it was important that semantic data link to other kinds of semantic data, ensuring the rise of a data-based web as interconnected as the existing web. Berners-Lee used the term “linked data” to describe this ideal scenario. Though “linked data” was in one sense just a recapitulation of the original vision for the Semantic Web, it became a term that people could rally around and thus amounted to a rebranding of the Semantic Web project.
Berners-Lee’s article launched the second phase of the Semantic Web’s development, where the focus shifted from setting standards and building toy examples to creating and popularizing large RDF datasets. Perhaps the most successful of these datasets was DBpedia, a giant repository of RDF triplets extracted from Wikipedia articles. DBpedia, which made heavy use of the Semantic Web standards that had been developed in the first half of the 2000s, was a standout example of what could be accomplished using the W3C’s new formats. Today DBpedia describes 4.58 million entities and is used by organizations like the NY Times, BBC, and IBM, which employed DBpedia as a knowledge source for IBM Watson, the Jeopardy-winning artificial intelligence system.
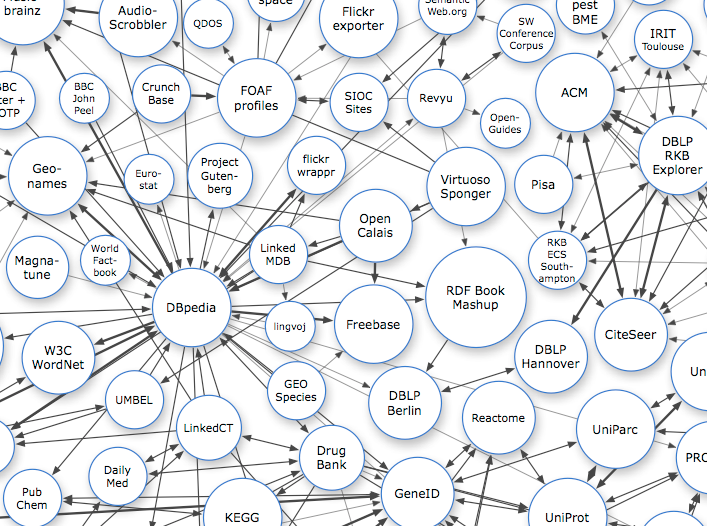
The third phase of the Semantic Web’s development involved adapting the W3C’s
standards to fit the actual practices and preferences of web developers. By
2008, JSON had begun its meteoric rise to popularity. Whereas XML came packaged
with a bunch of associated technologies of indeterminate purpose (XLST, XPath,
XQuery, XLink), JSON was just JSON. It was less verbose and more readable. Manu
Sporny, an entrepreneur and member of the W3C, had already started using JSON
at his company and wanted to find an easy way for RDFa and JSON to work
together.11 The result would be JSON-LD, which in essence was RDF reimagined
for a world that had chosen JSON over XML. Sporny, together with his CTO, Dave
Longley, issued a draft specification of JSON-LD in 2010. For the next few
years, JSON-LD and an updated RDF specification would be the primary focus of
Semantic Web work at the W3C. JSON-LD could be used on its own or it could be
embedded within a <script> tag on an HTML page, making it an alternative to
both RDF and RDFa.
Work on JSON-LD coincided with the development of schema.org, a centralized collection of simple schemas for describing things that might exist on the web. schema.org was started by Google, Bing, and Yahoo with the express purpose of delivering better search results by agreeing to a common set of vocabularies. schema.org vocabularies, together with JSON-LD, are now used to drive features like Google’s Knowledge Graph. The approach was a more practical and less abstract one, where immediate applications in search results were the focus. The schema.org team are careful to state on their website that they are not attempting to create a “universal ontology.”12
Today, work on the Semantic Web seems to have petered out. The W3C still does some work on the Semantic Web under the heading of “Data Activity,” which might charitably be called the fourth phase of the Semantic Web project. But it’s telling that the most recent “Data Activity” project is a study of what the W3C must do to improve its standardization process.13 Even the W3C now appears to recognize that few of its Semantic Web standards have been widely adopted and that simpler standards would have been more successful. The attitude at the W3C seems to be one of retrenchment and introspection, perhaps in the hope of being better prepared when the Semantic Web looks promising again.
A Lingering Legacy
And so the Semantic Web, as colorfully described by one person, is “as dead as last year’s roadkill.”14 At least, the version of the Semantic Web originally proposed by Tim Berners-Lee, which once seemed to be the imminent future of the web, is unlikely to emerge soon. That said, many of the technologies and ideas that were developed amid the push to create the Semantic Web have been repurposed and live on in various applications. As already mentioned, Google relies on Semantic Web technologies—now primarily JSON-LD—to generate useful conceptual summaries next to search results. schema.org maintains a list of “vocabularies” that web developers can use to publish easily understood data for a wide audience—it is a new, more practical imagining of what a public, shared ontology might look like. And to some degree, the many REST APIs now available constitute a diminished Semantic Web. What wasn’t possible in 2001 now is: You can easily build applications that make use of data from across the web. The difference is that you must sign up for each API one by one beforehand, which in addition to being wearisome also gives whoever hosts the API enormous control over how you access their data.
Another modern application of Semantic Web technologies, perhaps the most popular and successful in recent years outside of Google, is Facebook’s OpenGraph protocol. The OpenGraph protocol defines a schema that web developers can use (via RDFa) to determine how a web page is displayed when shared in a social media application. For example, a web developer working at the New York Times might use OpenGraph to specify the title and thumbnail that should appear when a New York Times article is shared in Facebook. In one sense, this is an application of Semantic Web technologies true to the Semantic Web’s origins in research on metadata. Tagging a webpage with extra information about who wrote it and what it is about is exactly the kind of metadata authoring the Semantic Web was going to depend on. But in another sense, OpenGraph is an application of Semantic Web technologies to further a purpose somewhat at odds with the philosophy of the web. The metadata isn’t meant to be general-purpose, after all. People tag their webpages using OpenGraph because they want links to their content to unfurl properly in Facebook. And the more information Facebook knows about your website, the closer Facebook gets to simply reproducing your entire website within Facebook, portending a future where the open web is a mythical land beyond Facebook’s towering blue walls.
What’s fascinating about JSON-LD and OpenGraph is that you can use them without knowing anything about subject-predicate-object triplets, RDF, RDF Schema, ontologies, OWL, or really any other Semantic Web technologies—you don’t even have to know XML. Manu Sporny has even said that the JSON-LD working group at W3C made a special effort to avoid references to RDF in the JSON-LD specification.15 This is almost certainly why these technologies have succeeded and continue to be popular. Nobody wants to use a tool that can only be fully understood by reading a whole family of specifications.
It’s interesting to consider what might have happened if simple formats like JSON-LD had appeared earlier. The Semantic Web could have sidestepped its fatal association with XML. More people might have been tempted to mark up their websites with RDF, but even that may not have saved the Semantic Web. Sean B. Palmer, an Internet Person that has scrubbed all biographical information about himself from the internet but who claims to have worked in the Semantic Web world for a while in the 2000s, posits that the real problem was the lack of a truly decentralized infrastructure to host the Semantic Web on.16 To host your own website, you need to buy a domain name from ICANN, configure it correctly using DNS, and then pay someone to host your content if you don’t already have a server of your own. We shouldn’t be surprised if the average person finds it easier to enter their information into a giant, corporate data repository. And in a web of giant, corporate data repositories, there are no compelling use cases for Semantic Web technologies.
So the problems that confronted the Semantic Web were more numerous and profound than just “XML sucks.” All the same, it’s hard to believe that the Semantic Web is truly dead and gone. Some of the particular technologies that the W3C dreamed up in the early 2000s may not have a future, but the decentralized vision of the web that Tim Berners-Lee and his fellow researchers described in Scientific American is too compelling to simply disappear. Imagine a web where, rather than filling out the same tedious form every time you register for a service, you were somehow able to authorize services to get that information from your own website. Imagine a Facebook that keeps your list of friends, hosted on your own website, up-to-date, rather than vice-versa. Basically, the Semantic Web was going to be a web where everyone gets to have their own personal REST API, whether they know the first thing about computers or not. Conceived of that way, it’s easy to see why the Semantic Web hasn’t yet been realized. There are so many engineering and security issues to sort out between here and there. But it’s also easy to see why the dream of the Semantic Web seduced so many people.
If you enjoyed this post, more like it come out every four weeks! Follow @TwoBitHistory on Twitter or subscribe to the RSS feed to make sure you know when a new post is out.
-
Berners-Lee, Tim, James Hendler, and Ora Lassila. “The Semantic Web.” Scientific American, May 2001, https://www-sop.inria.fr/acacia/cours/essi2006/Scientific%20American_%20Feature%20Article_%20The%20Semantic%20Web_%20May%202001.pdf. ↩
-
Shannon, Victoria. “A ‘more Revolutionary’ Web.” The New York Times, May 23, 2006. https://www.nytimes.com/2006/05/23/technology/23iht-web.html. ↩
-
Doctorow, Cory. “Metacrap: Putting the Torch to Seven Straw-men of the Meta-utopia.” August 26, 2001. Accessed May 26, 2018. https://people.well.com/user/doctorow/metacrap.htm. ↩
-
Doctorow, Cory. “‘Metacrap’ and the History of the Semantic Web.” E-mail message to author. May 11, 2018. ↩
-
Munat, Ben. “The Lowercase Semantic Web: Using Semantics on the Existing World Wide Web.” May 2004. Accessed May 26, 2018. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.85.3445&rep=rep1&type=pdf. ↩
-
Swartz, Aaron. A Programmable Web: An Unfinished Work. Morgan and Claypool, 2013. March 12, 2013. Accessed May 26, 2018. https://upload.wikimedia.org/wikipedia/commons/3/3f/Aaron_Swartz_s_A_Programmable_Web_An_Unfinished_Work.pdf. ↩
-
Palmer, Sean B. “What Happened to the Semantic Web?” October 11, 2017. SW-forum Web. Accessed May 26, 2018. http://lists.w3.org/Archives/Public/public-lod/2017Oct/0003.html. ↩
-
Bray, Tim. “The RDF.net Challenge.” Ongoing by Tim Bray. May 21, 2003. Accessed May 26, 2018. https://www.tbray.org/ongoing/When/200x/2003/05/21/RDFNet. ↩
-
Bray, Tim, and Joshua Tauberer. “What Is RDF.” XML.com. July 26, 2006. Accessed May 26, 2018. http://www.xml.com/pub/a/2001/01/24/rdf.html. ↩
-
Berners-Lee, Tim. “Linked Data.” W3C. June 18, 2009. Accessed May 26, 2018. https://www.w3.org/DesignIssues/LinkedData.html. ↩
-
Sporny, Manu. “The Origins of JSON-LD.” The Beautiful, Tormented Machine. January 19, 2014. Accessed May 26, 2018. http://manu.sporny.org/2014/json-ld-origins/. ↩
-
“Data Model.” Schema.org. Accessed May 26, 2018. http://schema.org/docs/datamodel.html. ↩
-
Raggett, Dave. “W3C Study of Practices and Tooling for Web Data Standardisation.” W3C. December 2017. Accessed May 26, 2018. https://www.w3.org/2017/12/odi-study/. ↩
-
Rochkind, Jonathan. “Is the Semantic Web Still a Thing?” Bibliographic Wilderness. October 28, 2014. Accessed May 26, 2018. https://bibwild.wordpress.com/2014/10/28/is-the-semantic-web-still-a-thing/. Quoting Hacker News user “bane.” https://news.ycombinator.com/item?id=8510970. ↩
-
Sporny, Manu. “JSON-LD and Why I Hate the Semantic Web.” The Beautiful, Tormented Machine. January 21, 2014. Accessed May 26, 2018. http://manu.sporny.org/2014/json-ld-origins-2/. ↩
-
Palmer, Sean B. ↩