

This post was originally published on September 16th, 2018. What follows is a revision that includes additional information gleaned from interviews with Ramanathan Guha, Ian Davis, Dan Libby, and Kevin Werbach.
A version of this post was also published by Vice News.
About a decade ago, the average internet user might well have heard of RSS. Really Simple Syndication, or Rich Site Summary—what the acronym stands for depends on who you ask—is a standard that websites and podcasts can use to offer a feed of content to their users, one easily understood by lots of different computer programs. Today, though RSS continues to power many applications on the web, it has become, for most people, an obscure technology.
The story of how this happened is really two stories. The first is a story about a broad vision for the web’s future that never quite came to fruition. The second is a story about how a collaborative effort to improve a popular standard devolved into one of the most contentious forks in the history of open-source software development.
In the late 1990s, in the go-go years between Netscape’s IPO and the Dot-com crash, everyone could see that the web was going to be an even bigger deal than it already was, even if they didn’t know exactly how it was going to get there. One theory was that the web was about to be revolutionized by syndication. The web, originally built to enable a simple transaction between two parties—a client fetching a document from a single host server—would be broken open by new standards that could be used to repackage and redistribute entire websites through a variety of channels. Kevin Werbach, writing for Release 1.0, a newsletter influential among investors in the 1990s, predicted that syndication “would evolve into the core model for the Internet economy, allowing businesses and individuals to retain control over their online personae while enjoying the benefits of massive scale and scope.”1
He invited his readers to imagine a future in which fencing aficionados, rather than going directly to an “online sporting goods site” or “fencing equipment retailer,” could buy a new épée directly through e-commerce widgets embedded into their favorite website about fencing.2 Just like in the television world, where big networks syndicate their shows to smaller local stations, syndication on the web would allow businesses and publications to reach consumers through a multitude of intermediary sites. This would mean, as a corollary, that consumers would gain significant control over where and how they interacted with any given business or publication on the web.
RSS was one of the standards that promised to deliver this syndicated future. To Werbach, RSS was “the leading example of a lightweight syndication protocol.”3 Another contemporaneous article called RSS the first protocol to realize the potential of XML.4 It was going to be a way for both users and content aggregators to create their own customized channels out of everything the web had to offer. And yet, two decades later, after the rise of social media and Google’s decision to shut down Google Reader, RSS appears to be a slowly dying technology, now used chiefly by podcasters, programmers with tech blogs, and the occasional journalist. Though of course some people really do still rely on RSS readers, stubbornly adding an RSS feed to your blog, even in 2018, is a political statement. That little tangerine bubble has become a wistful symbol of defiance against a centralized web increasingly controlled by a handful of corporations, a web that hardly resembles the syndicated web of Werbach’s imagining.
The future once looked so bright for RSS. What happened? Was its downfall inevitable, or was it precipitated by the bitter infighting that thwarted the development of a single RSS standard?
Muddied Water
RSS was invented twice. This meant it never had an obvious owner, a state of affairs that spawned endless debate and acrimony. But it also suggests that RSS was an important idea whose time had come.
In 1998, Netscape was struggling to envision a future for itself. Its flagship product, the Netscape Navigator web browser—once preferred by over 80 percent of web users—was quickly losing ground to Microsoft’s Internet Explorer. So Netscape decided to compete in a new arena. In May, a team was brought together to start work on what was known internally as “Project 60.”5 Two months later, Netscape announced “My Netscape,” a web portal that would fight it out with other portals like Yahoo, MSN, and Excite.
The following year, in March, Netscape announced an addition to the My Netscape portal called the “My Netscape Network.” My Netscape users could now customize their My Netscape page so that it contained “channels” featuring the most recent headlines from sites around the web. As long as your favorite website published a special file in a format dictated by Netscape, you could add that website to your My Netscape page, typically by clicking an “Add Channel” button that participating websites were supposed to add to their interfaces. A little box containing a list of linked headlines would then appear.
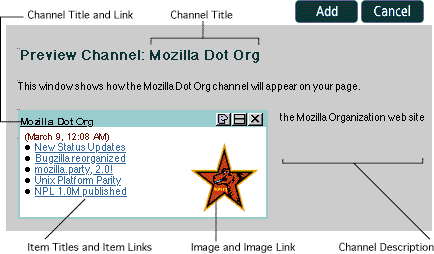 A My Netscape Network channel for Mozilla.org, as it might look to users
A My Netscape Network channel for Mozilla.org, as it might look to users
about to add it to their My Netscape page.
The special file that participating websites had to publish was an RSS file. In the My Netscape Network announcement, Netscape explained that RSS stood for “RDF Site Summary.”6 This was somewhat of a misnomer. RDF, or the Resource Description Framework, is basically a grammar for describing certain properties of arbitrary resources. (See my article about the Semantic Web if that sounds really exciting to you.) In 1999, a draft specification for RDF was being considered by the World Wide Web Consortium (W3C), the web’s main standards body. Though RSS was supposed to be based on RDF, the example RSS document Netscape actually released didn’t use any RDF tags at all. In a document that accompanied the Netscape RSS specification, Dan Libby, one of the specification’s authors, explained that “in this release of MNN, Netscape has intentionally limited the complexity of the RSS format.”7 The specification was given the 0.90 version number, the idea being that subsequent versions would bring RSS more in line with the W3C’s XML specification and the evolving draft of the RDF specification.
RSS had been created by Libby and two other Netscape employees, Eckart Walther and Ramanathan Guha. According to an email to me from Guha, he and Walther cooked up RSS in the beginning with some input from Libby; after AOL bought Netscape in 1998, he and Walther left and it became Libby’s responsibility. Before Netscape, Guha had worked for Apple, where he came up with something called the Meta Content Framework. MCF was a format for representing metadata about anything from web pages to local files. Guha demonstrated its power by developing an application called HotSauce that visualized relationships between files as a network of nodes suspended in 3D space. Immediately after leaving Apple for Netscape, Guha worked with a Netscape consultant named Tim Bray, who in a post on his blog said that he and Guha eventually produced an XML-based version of MCF that in turn became the foundation for the W3C’s RDF draft.8 It’s no surprise, then, that Guha, Walther, and Libby were keen to build on Guha’s prior work and incorporate RDF into RSS. But Libby later wrote that the original vision for an RDF-based RSS was pared back because of time constraints and the perception that RDF was “‘too complex’ for the ‘average user.’”9
While Netscape was trying to win eyeballs in what became known as the “portal wars,” elsewhere on the web a new phenomenon known as “weblogging” was being pioneered.10 One of these pioneers was Dave Winer, CEO of a company called UserLand Software, which developed early content management systems that made blogging accessible to people without deep technical fluency. Winer ran his own blog, Scripting News, which today is one of the oldest blogs on the internet. More than a year before Netscape announced My Netscape Network, on December 15, 1997, Winer published a post announcing that the blog would now be available in XML as well as HTML.11
Dave Winer’s XML format became known as the Scripting News format. It was supposedly similar to Microsoft’s Channel Definition Format (a “push technology” standard submitted to the W3C in March, 1997), but I haven’t been able to find a file in the original format to verify that claim.12 Like Netscape’s RSS, it structured the content of Winer’s blog so that it could be understood by other software applications. When Netscape released RSS 0.90, Winer and UserLand Software began to support both formats. But Winer believed that Netscape’s format was “woefully inadequate” and “missing the key thing web writers and readers need.”13 It could only represent a list of links, whereas the Scripting News format could represent a series of paragraphs, each containing one or more links.
In June 1999, two months after Netscape’s My Netscape Network announcement,
Winer introduced a new version of the Scripting News format, called
ScriptingNews 2.0b1. Winer claimed that he decided to move ahead with his own
format only after trying but failing to get anyone at Netscape to care about
RSS 0.90’s deficiencies.14 The new version of the Scripting News format
added several items to the <header> element that brought the Scripting News
format to parity with RSS. But the two formats continued to differ in that the
Scripting News format, which Winer nicknamed the “fat” syndication format,
could include entire paragraphs and not just links.
Netscape got around to releasing RSS 0.91 the very next month. The updated specification was a major about-face. RSS no longer stood for “RDF Site Summary”; it now stood for “Rich Site Summary.” All the RDF—and there was almost none anyway—was stripped out. Many of the Scripting News tags were incorporated. In the text of the new specification, Libby explained:
RDF references removed. RSS was originally conceived as a metadata format providing a summary of a website. Two things have become clear: the first is that providers want more of a syndication format than a metadata format. The structure of an RDF file is very precise and must conform to the RDF data model in order to be valid. This is not easily human-understandable and can make it difficult to create useful RDF files. The second is that few tools are available for RDF generation, validation and processing. For these reasons, we have decided to go with a standard XML approach.15
Winer was enormously pleased with RSS 0.91, calling it “even better than I thought it would be.”16 UserLand Software adopted it as a replacement for the existing ScriptingNews 2.0b1 format. For a while, it seemed that RSS finally had a single authoritative specification.
The Great Fork
A year later, the RSS 0.91 specification had become woefully inadequate. There were all sorts of things people were trying to do with RSS that the specification did not address. There were other parts of the specification that seemed unnecessarily constraining—each RSS channel could only contain a maximum of 15 items, for example.
By that point, RSS had been adopted by several more organizations. Other than Netscape, which seems to have lost interest after RSS 0.91, the big players were Dave Winer’s UserLand Software; O’Reilly Net, which ran an RSS aggregator called Meerkat; and Moreover.com, which also ran an RSS aggregator focused on news.17 Via mailing list, representatives from these organizations and others regularly discussed how to improve on RSS 0.91. But there were deep disagreements about what those improvements should look like.
The mailing list in which most of the discussion occurred was called the Syndication mailing list. An archive of the Syndication mailing list is still available. It is an amazing historical resource. It provides a moment-by-moment account of how those deep disagreements eventually led to a political rupture of the RSS community.
On one side of the coming rupture was Winer. Winer was impatient to evolve RSS, but he wanted to change it only in relatively conservative ways. In June, 2000, he published his own RSS 0.91 specification on the UserLand website, meant to be a starting point for further development of RSS. It made no significant changes to the 0.91 specification published by Netscape. Winer claimed in a blog post that accompanied his specification that it was only a “cleanup” documenting how RSS was actually being used in the wild, which was needed because the Netscape specification was no longer being maintained.18 In the same post, he argued that RSS had succeeded so far because it was simple, and that by adding namespaces (a way to explicitly distinguish between different RSS vocabularies) or RDF back to the format—some had suggested this be done in the Syndication mailing list—it “would become vastly more complex, and IMHO, at the content provider level, would buy us almost nothing for the added complexity.” In a message to the Syndication mailing list sent around the same time, Winer suggested that these issues were important enough that they might lead him to create a fork:
I’m still pondering how to move RSS forward. I definitely want ICE-like stuff in RSS2, publish and subscribe is at the top of my list, but I am going to fight tooth and nail for simplicity. I love optional elements. I don’t want to go down the namespaces and schema road, or try to make it a dialect of RDF. I understand other people want to do this, and therefore I guess we’re going to get a fork. I have my own opinion about where the other fork will lead, but I’ll keep those to myself for the moment at least.19
Arrayed against Winer were several other people, including Rael Dornfest of O’Reilly, Ian Davis (responsible for a search startup called Calaba), and a precocious, 14-year-old Aaron Swartz. This is the same Aaron Swartz that would later co-found Reddit and become famous for his hacktivism. (In 2000, according to an email to me from Davis, his dad often accompanied him to technology meetups.) Dornfest, Davis, and Swartz all thought that RSS needed namespaces in order to accommodate the many different things everyone wanted to do with it. On another mailing list hosted by O’Reilly, Davis proposed a namespace-based module system, writing that such a system would “make RSS as extensible as we like rather than packing in new features that over-complicate the spec.”20 The “namespace camp” believed that RSS would soon be used for much more than the syndication of blog posts, so namespaces, rather than being a complication, were the only way to keep RSS from becoming unmanageable as it supported more and more use cases.
At the root of this disagreement about namespaces was a deeper disagreement about what RSS was even for. Winer had invented his Scripting News format to syndicate the posts he wrote for his blog. Netscape had released RSS as “RDF Site Summary” because it was a way of recreating a site in miniature within the My Netscape online portal. Some people felt that Netscape’s original vision should be honored. Writing to the Syndication mailing list, Davis explained his view that RSS was “originally conceived as a way of building mini sitemaps,” and that now he and others wanted to expand RSS “to encompass more types of information than simple news headlines and to cater for the new uses of RSS that have emerged over the last 12 months.”21 This was a sensible point to make because the goal of the Netscape RSS project in the beginning was even loftier than Davis suggests: Guha told me that he wanted to create a technology that could support not just website channels but feeds about arbitrary entities such as, for example, Madonna. Further developing RSS so that it could do this would indeed be in keeping with that original motivation. But Davis’ argument also overstates the degree to which there was a unified vision at Netscape by the time the RSS specification was published. According to Libby, who I talked to via email, there was eventually contention between a “Let’s Build the Semantic Web” group and “Let’s Make This Simple for People to Author” group even within Netscape.
For his part, Winer argued that Netscape’s original goals were irrelevant because his Scripting News format was in fact the first RSS and it had been meant for a very different purpose. Given that the people most involved in the development of RSS disagreed about who had created RSS and why, a fork seems to have been inevitable.
The fork happened after Dornfest announced a proposed RSS 1.0 specification and formed the RSS-DEV Working Group—which would include Davis, Swartz, and several others but not Winer—to get it ready for publication. In the proposed specification, RSS once again stood for “RDF Site Summary,” because RDF had been added back in to represent metadata properties of certain RSS elements. The specification acknowledged Winer by name, giving him credit for popularizing RSS through his “evangelism.”22 But it also argued that RSS could not be improved in the way that Winer was advocating. Just adding more elements to RSS without providing for extensibility with a module system would “sacrifice scalability.” The specification went on to define a module system for RSS based on XML namespaces.
Winer felt that it was “unfair” that the RSS-DEV Working Group had arrogated
the “RSS 1.0” name for themselves.23 In another mailing list about
decentralization, he wrote that he had “recently had a standard stolen by a big
name,” presumably meaning O’Reilly, which had convened the RSS-DEV Working
Group.24 Other members of the Syndication mailing list also felt that the
RSS-DEV Working Group should not have used the name “RSS” without unanimous
agreement from the community on how to move RSS forward. But the Working Group
stuck with the name. Dan Brickley, another member of the RSS-DEV Working Group,
defended this decision by arguing that “RSS 1.0 as proposed is solidly grounded
in the original RSS vision, which itself had a long heritage going back to MCF
(an RDF precursor) and related specs (CDF etc).”25 He essentially felt that
the RSS 1.0 effort had a better claim to the RSS name than Winer did, since RDF
had originally been a part of RSS. The RSS-DEV Working Group published a final
version of their specification in December. That same month, Winer published
his own improvement to RSS 0.91, which he called RSS 0.92, on UserLand’s
website. RSS 0.92 made several small optional improvements to RSS, among which
was the addition of the <enclosure> tag soon used by podcasters everywhere.
RSS had officially forked.
The fork might have been avoided if a better effort had been made to include Winer in the RSS-DEV Working Group. He obviously belonged there. He was a prominent contributor to the Syndication mailing list and responsible for much of RSS’ popularity, as the members of the Working Group themselves acknowledged. But, as Davis wrote in an email to me, Winer “wanted control and wanted RSS to be his legacy so was reluctant to work with us.” Tim O’Reilly, founder and CEO of O’Reilly, explained in a UserLand discussion group in September, 2000 that Winer basically refused to participate:
A group of people involved in RSS got together to start thinking about its future evolution. Dave was part of the group. When the consensus of the group turned in a direction he didn’t like, Dave stopped participating, and characterized it as a plot by O’Reilly to take over RSS from him, despite the fact that Rael Dornfest of O’Reilly was only one of about a dozen authors of the proposed RSS 1.0 spec, and that many of those who were part of its development had at least as long a history with RSS as Dave had.26
To this, Winer said:
I met with Dale [Dougherty] two weeks before the announcement, and he didn’t say anything about it being called RSS 1.0. I spoke on the phone with Rael the Friday before it was announced, again he didn’t say that they were calling it RSS 1.0. The first I found out about it was when it was publicly announced.
Let me ask you a straight question. If it turns out that the plan to call the new spec “RSS 1.0” was done in private, without any heads-up or consultation, or for a chance for the Syndication list members to agree or disagree, not just me, what are you going to do?
UserLand did a lot of work to create and popularize and support RSS. We walked away from that, and let your guys have the name. That’s the top level. If I want to do any further work in Web syndication, I have to use a different name. Why and how did that happen Tim?27
I have not been able to find a discussion in the Syndication mailing list about using the RSS 1.0 name prior to the announcement of the RSS 1.0 proposal. Winer, in a message to me, said that he was not trying to control RSS and just wanted to use it in his products.
RSS would fork again in 2003, when several developers frustrated with the bickering in the RSS community sought to create an entirely new format. These developers created Atom, a format that did away with RDF but embraced XML namespaces. Atom would eventually be specified by a proposed IETF standard. After the introduction of Atom, there were three competing versions of RSS: Winer’s RSS 0.92 (updated to RSS 2.0 in 2002 and renamed “Really Simple Syndication”), the RSS-DEV Working Group’s RSS 1.0, and Atom.
Decline
The proliferation of competing RSS specifications may have hampered RSS in other ways that I’ll discuss shortly. But it did not stop RSS from becoming enormously popular during the 2000s. By 2004, the New York Times had started offering its headlines in RSS and had written an article explaining to the layperson what RSS was and how to use it.28 Google Reader, the RSS aggregator ultimately used by millions, was launched in 2005. By 2013, RSS seemed popular enough that the New York Times, in its obituary for Aaron Swartz, called the technology “ubiquitous.”29 For a while, before a third of the planet had signed up for Facebook, RSS was simply how many people stayed abreast of news on the internet.
The New York Times published Swartz’ obituary in January 2013. By that point, though, RSS had actually turned a corner and was well on its way to becoming an obscure technology. Google Reader was shut down in July 2013, ostensibly because user numbers had been falling “over the years.”30 This prompted several articles from various outlets declaring that RSS was dead. But people had been declaring that RSS was dead for years, even before Google Reader’s shuttering. Steve Gillmor, writing for TechCrunch in May 2009, advised that “it’s time to get completely off RSS and switch to Twitter” because “RSS just doesn’t cut it anymore.”31 He pointed out that Twitter was basically a better RSS feed, since it could show you what people thought about an article in addition to the article itself. It allowed you to follow people and not just channels. Gillmor told his readers that it was time to let RSS recede into the background. He ended his article with a verse from Bob Dylan’s “Forever Young.”
Today, RSS is not dead. But neither is it anywhere near as popular as it once was. Lots of people have offered explanations for why RSS lost its broad appeal. Perhaps the most persuasive explanation is exactly the one offered by Gillmor in 2009. Social networks, just like RSS, provide a feed featuring all the latest news on the internet. Social networks took over from RSS because they were simply better feeds. They also provide more benefits to the companies that own them. Some people have accused Google, for example, of shutting down Google Reader in order to encourage people to use Google+. Google might have been able to monetize Google+ in a way that it could never have monetized Google Reader. Marco Arment, the creator of Instapaper, wrote on his blog in 2013:
Google Reader is just the latest casualty of the war that Facebook started, seemingly accidentally: the battle to own everything. While Google did technically “own” Reader and could make some use of the huge amount of news and attention data flowing through it, it conflicted with their far more important Google+ strategy: they need everyone reading and sharing everything through Google+ so they can compete with Facebook for ad-targeting data, ad dollars, growth, and relevance.32
So both users and technology companies realized that they got more out of using social networks than they did out of RSS.
Another theory is that RSS was always too geeky for regular people. Even the New York Times, which seems to have been eager to adopt RSS and promote it to its audience, complained in 2006 that RSS is a “not particularly user friendly” acronym coined by “computer geeks.”33 Before the RSS icon was designed in 2004, websites like the New York Times linked to their RSS feeds using little orange boxes labeled “XML,” which can only have been intimidating.34 The label was perfectly accurate though, because back then clicking the link would take a hapless user to a page full of XML. This great tweet captures the essence of this explanation for RSS’ demise. Regular people never felt comfortable using RSS; it hadn’t really been designed as a consumer-facing technology and involved too many hurdles; people jumped ship as soon as something better came along.
RSS might have been able to overcome some of these limitations if it had been further developed. Maybe RSS could have been extended somehow so that friends subscribed to the same channel could syndicate their thoughts about an article to each other. Maybe browser support could have been improved. But whereas a company like Facebook was able to “move fast and break things,” the RSS developer community was stuck trying to achieve consensus. When they failed to agree on a single standard, effort that could have gone into improving RSS was instead squandered on duplicating work that had already been done. Davis told me, for example, that Atom would not have been necessary if the members of the Syndication mailing list had been able to compromise and collaborate, and “all that cleanup work could have been put into RSS to strengthen it.” So if we are asking ourselves why RSS is no longer popular, a good first-order explanation is that social networks supplanted it. If we ask ourselves why social networks were able to supplant it, then the answer may be that the people trying to make RSS succeed faced a problem much harder than, say, building Facebook. As Dornfest wrote to the Syndication mailing list at one point, “currently it’s the politics far more than the serialization that’s far from simple.”35
So today we are left with centralized silos of information. Even so, the syndicated web that Werbach foresaw in 1999 has been realized, just not in the way he thought it would be. After all, The Onion is a publication that relies on syndication through Facebook and Twitter the same way that Seinfeld relied on syndication to rake in millions after the end of its original run. I asked Werbach what he thinks about this and he more or less agrees. He told me that RSS, on one level, was clearly a failure, because it isn’t now “a technology that is really the core of the whole blogging world or content world or world of assembling different elements of things into sites.” But, on another level, “the whole social media revolution is partly about the ability to aggregate different content and resources” in a manner reminiscent of RSS and his original vision for a syndicated web. To Werbach, “it’s the legacy of RSS, even if it’s not built on RSS.”
Unfortunately, syndication on the modern web still only happens through one of a very small number of channels, meaning that none of us “retain control over our online personae” the way that Werbach imagined we would. One reason this happened is garden-variety corporate rapaciousness—RSS, an open format, didn’t give technology companies the control over data and eyeballs that they needed to sell ads, so they did not support it. But the more mundane reason is that centralized silos are just easier to design than common standards. Consensus is difficult to achieve and it takes time, but without consensus spurned developers will go off and create competing standards. The lesson here may be that if we want to see a better, more open web, we have to get better at not screwing each other over.
If you enjoyed this post, more like it come out every four weeks! Follow @TwoBitHistory on Twitter or subscribe to the RSS feed to make sure you know when a new post is out.
Previously on TwoBitHistory…
I've long wondered if the Unix commands on my Macbook are built from the same code that they were built from 20 or 30 years ago. The answer, it turns, out, is "kinda"!
— TwoBitHistory (@TwoBitHistory) November 12, 2018
My latest post, on how the implementation of cat has changed over the years:https://t.co/dHizjK50ES
-
Kevin Werbach, “The Web Goes into Syndication,” Release 1.0, July 22, 1999, 1, accessed September 14, 2018, http://cdn.oreillystatic.com/radar/r1/07-99.pdf. ↩
-
ibid. ↩
-
Werbach, 8. ↩
-
Peter Wiggin, “RSS Delivers the XML Promise,” Web Review, October 29, 1999, accessed September 14, 2018, https://people.apache.org/~jim/NewArchitect/webrevu/1999/10_29/webauthors/10_29_99_2a.html. ↩
-
Ben Hammersley, RSS and Atom (O’Reilly), 8, accessed September 14, 2018, https://books.google.com/books?id=kwJVAgAAQBAJ. ↩
-
“RSS 0.90 Specification,” RSS Advisory Board, accessed September 14, 2018, http://www.rssboard.org/rss-0-9-0. ↩
-
“My Netscape Network Future Directions,” RSS Advisory Board, accessed September 14, 2018, http://www.rssboard.org/mnn-futures. ↩
-
Tim Bray, “The RDF.net Challenge,” Ongoing by Tim Bray, May 21, 2003, accessed September 14, 2018, https://www.tbray.org/ongoing/When/200x/2003/05/21/RDFNet. ↩
-
Dan Libby, “RSS: Introducing Myself,” August 24, 2000, RSS-DEV Mailing List, accessed September 14, 2018, https://groups.yahoo.com/neo/groups/rss-dev/conversations/topics/239. ↩
-
Alexandra Krasne, “Browser Wars May Become Portal Wars,” CNN, accessed September 14, 2018, http://www.cnn.com/TECH/computing/9910/04/portal.war.idg/index.html. ↩
-
Dave Winer, “Scripting News in XML,” Scripting News, December 15, 1997, accessed September 14, 2018, http://scripting.com/davenet/1997/12/15/scriptingNewsInXML.html. ↩
-
Joseph Reagle, “RSS History,” 2004, accessed September 14, 2018, https://reagle.org/joseph/2003/rss-history.html. ↩
-
Dave Winer, “A Faceoff with Netscape,” Scripting News, June 16, 1999, accessed September 14, 2018, http://scripting.com/davenet/1999/06/16/aFaceOffWithNetscape.html. ↩
-
ibid. ↩
-
Dan Libby, “RSS 0.91 Specification (Netscape),” RSS Advisory Board, accessed September 14, 2018, http://www.rssboard.org/rss-0-9-1-netscape. ↩
-
Dave Winer, “Scripting News: 7/28/1999,” Scripting News, July 28, 1999, accessed September 14, 2018, http://scripting.com/1999/07/28.html. ↩
-
Oliver Willis, “RSS Aggregators?” June 19, 2000, Syndication Mailing List, accessed September 14, 2018, https://groups.yahoo.com/neo/groups/syndication/conversations/topics/173. ↩
-
Dave Winer, “Scripting News: 07/07/2000,” Scripting News, July 07, 2000, accessed September 14, 2018, http://essaysfromexodus.scripting.com/backissues/2000/06/07/#rss. ↩
-
Dave Winer, “Re: RSS 0.91 Restarted,” June 9, 2000, Syndication Mailing List, accessed September 14, 2018, https://groups.yahoo.com/neo/groups/syndication/conversations/topics/132. ↩
-
Leigh Dodds, “RSS Modularization,” XML.com, July 5, 2000, accessed September 14, 2018, http://www.xml.com/pub/a/2000/07/05/deviant/rss.html. ↩
-
Ian Davis, “Re: [syndication] RSS Modularization Demonstration,” June 28, 2000, Syndication Mailing List, accessed September 14, 2018, https://groups.yahoo.com/neo/groups/syndication/conversations/topics/188. ↩
-
“RDF Site Summary (RSS) 1.0,” December 09, 2000, accessed September 14, 2018, http://web.resource.org/rss/1.0/spec. ↩
-
Dave Winer, “Re: [syndication] Re: Thoughts, Questions, and Issues,” August 16, 2000, Syndication Mailing List, accessed September 14, 2018, https://groups.yahoo.com/neo/groups/syndication/conversations/topics/410. ↩
-
Mark Pilgrim, “History of the RSS Fork,” Dive into Mark, September 5, 2002, accessed September 14, 2018, http://www.diveintomark.link/2002/history-of-the-rss-fork. ↩
-
Dan Brickley, “RSS-Classic, RSS 1.0 and a Historical Debt,” November 7, 2000, Syndication Mailing List, accessed September 14, 2018, https://groups.yahoo.com/neo/groups/rss-dev/conversations/topics/1136. ↩
-
Tim O’Reilly, “Re: Asking Tim,” UserLand, September 20, 2000, accessed September 14, 2018, http://static.userland.com/userLandDiscussArchive/msg021537.html. ↩
-
Dave Winer, “Re: Asking Tim,” UserLand, September 20, 2000, accessed September 14, 2018, http://static.userland.com/userLandDiscussArchive/msg021560.html. ↩
-
John Quain, “BASICS; Fine-Tuning Your Filter for Online Information,” The New York Times, 2004, accessed September 14, 2018, https://www.nytimes.com/2004/06/03/technology/basics-fine-tuning-your-filter-for-online-information.html. ↩
-
John Schwartz, “Aaron Swartz, Internet Activist, Dies at 26,” The New York Times, January 12, 2013, accessed September 14, 2018, https://www.nytimes.com/2013/01/13/technology/aaron-swartz-internet-activist-dies-at-26.html. ↩
-
“A Second Spring of Cleaning,” Official Google Blog, March 13, 2013, accessed September 14, 2018, https://googleblog.blogspot.com/2013/03/a-second-spring-of-cleaning.html. ↩
-
Steve Gillmor, “Rest in Peace, RSS,” TechCrunch, May 5, 2009, accessed September 14, 2018, https://techcrunch.com/2009/05/05/rest-in-peace-rss/. ↩
-
Marco Arment, “Lockdown,” Marco.org, July 3, 2013, accessed September 14, 2018, https://marco.org/2013/07/03/lockdown. ↩
-
Bob Tedeschi, “There’s a Popular New Code for Deals: RSS,” The New York Times, January 29, 2006, accessed September 14, 2018, https://www.nytimes.com/2006/01/29/travel/theres-a-popular-new-code-for-deals-rss.html. ↩
-
“NYTimes.com RSS Feeds,” The New York Times, accessed September 14, 2018, https://web.archive.org/web/20050326065348/www.nytimes.com/services/xml/rss/index.html. ↩
-
Rael Dornfest, “RE: Re: [syndication] RE: RFC: Clearing Confusion for RSS, Agreement for Forward Motion,” May 31, 2001, Syndication Mailing List, accessed September 14, 2018, https://groups.yahoo.com/neo/groups/syndication/conversations/messages/1717. ↩